
明けましておめでとうございます。今年もよろしくおねがいします。
このブログでは昨年の振り返りと今年の目標についてのブログにしていきたいと思います。
昨年の振り返り
- カテゴリー別ブログ投稿数
- 全体ブログ閲覧数ランキング
カテゴリー別ブログ投稿数
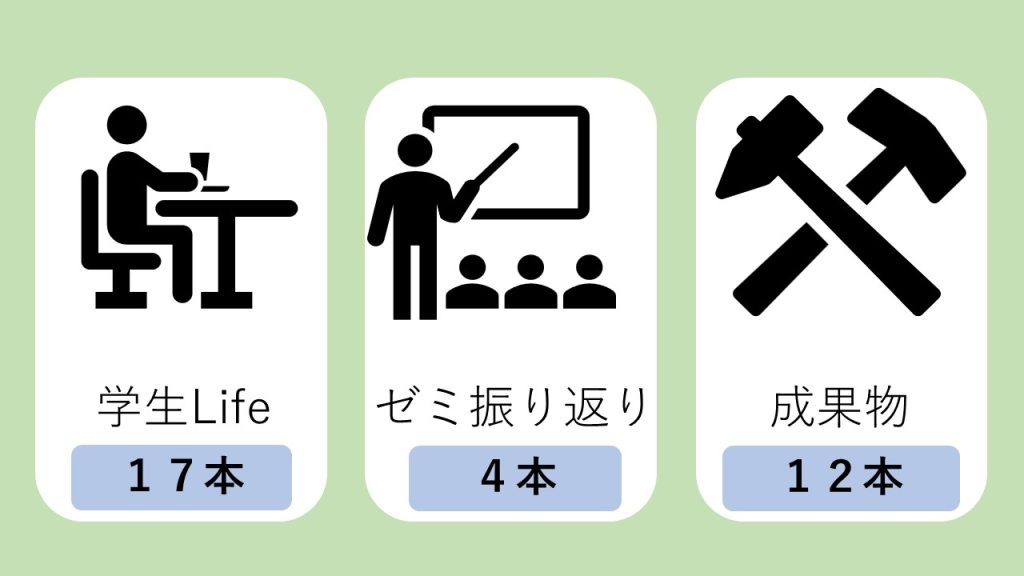
合計33本でした!
後期から始めたゼミの振り返りはとても読みごたえのあるブログになっています。お互いが振り返ることで、別の視点でも考えることができ、実際どのように自分のものにしていくか、今後どのようにしていくかが述べられていていました。研究室の活動を残しつつ、高校生にも大学の活動について知っていただけるように続けていきたいと思います!
全体ブログ閲覧数ランキング
3位 PythonでWebスクレイピング
magnetが書いたPythonでスクレイピングを実際に行ったブログが第3位でした!
授業の振り返りで行った内容をブログにしました。実際のPythonのコードも公開しています!コメントも丁寧にあるのが印象的でした。スクレイピングは便利な半面、使い方を間違えるとサイトに負荷をかけるものなので注意も必要ですね!
2位 話題の「Midjourney」を使ってみました!
AIを使った画像生成ツールのブログが第2位でした!
大学の授業でAIについて学習したのをきっかけに、AIが活用されているツールを紹介したブログになります。キーワードをもとにAIが自動で画像を生成するツールで、とても話題になりました!現在ではたくさんのツールが出てきました。SNSでも手軽にAIの画像生成が使われていて、私達の生活の周りにAIが近づいているように感じます。
教材としても使いやすいものになるので、高校の情報や技術科の教材としての活用も近い未来に行われるかもしれないですね
1位 LINEのAPIを使いこなそう!
Pythonで行うLINEAPIの紹介を行ったブログが第1位でした!
Pythonの学習で最初に何をしたらいいのかわからない方にとてもおすすめなツールです。とても簡単に実装をすることができます。
最近では、Youtubeでも解説している動画もたくさんあるので動画を見ながら学習を行うこともアリです!
来年度の目標
昨年度の上半期は授業の振り返りを行ったブログが多く、下半期はゼミの振り返りを行ったブログが投稿されました。現在のゼミのメンバーは7人もいるにも関わらず、下半期はかなりサボってしまいました。反省の限りです。上級生としてもっとできたことがあったのではないかと思ってしまいます。来年度もこのような事態にならないように、原因の分析と対策を行っていきたいです。
来年度の目標
- 投稿本数100本以上
- 全員が投稿できるような雰囲気づくり
- 後輩への引き継ぎ
これらを目標に一年間行っていきたいと思います!
また、より多くの方に知っていただけるようにWordPressの理解を深めていくことも必要になっていくと思います。学び続けることを忘れず、前進し続けたいと思います!
今年も小倉研究室をよろしくお願いします。